So, imagine that you have a herd of sheep - a very large herd. Say there's 10,000 sheep. And you know that 10% of the sheep are sick, and you need to run a test on this illness. However, you can't tell if a sheep is sick from the outside- you have to put it in the fancy testing machinery to figure it out. So, how do you find a sick sheep? Well, you probably start by picking one at random. And you have a 1 in 10 chance that you guess right. So, the question that I want to pose is: how likely is it that you choose, say, 100 sheep at random and STILL do not find a sick one?
So, you might wonder why is this question relevant. Let me put it in computer science terms - not graphs yet, but we'll get there. The reason this question exists is because doing things "randomly", generating truly random numbers is a lot of work for a computer. Sure, it can still do it quite fast, but it's costly in terms of running time and memory. So, if you pick one purely random sheep, then another purely random sheep, then another and another --- this gets costly. The probability that in 100 steps you still do NOT find a sick sheep (or a certain file, or whathaveyou in computer science terms) is fairly easy to calculate.
So, where does Spectral Theory come into this? We aren't computer scientists - or even theoretical computer scientists (which is a field! I had no idea, but it sounds fascinating.) Well, it turns out that a much nicer way in terms of computer power to do this searching for sick sheep is to put a 'graph structure' on the herd. What does that mean? Just give all the sheep numbers - 1 through 10,000. And then decide how you want the sheep to be connected to each other - one simple way is to say that sheep 2 is connected to sheep 1, sheep 3, and sheep 10,000, for example. Let every sheep be "connected" to three others. (Bear with me, sounds weird, I know)
In doing this 'connecting' thing, we are turning the herd of sheep into a "3-regular" graph. That simply means that every vertex (or dot) in the graph has exactly 3 neighbors - three edges (or lines) coming to it. Here are some examples of three regular graphs - the first, second, and fourth graphs are 3-regular. The third and fifth are not. Notice that the first, second, fourth, and fifth are all graphs on 6 vertices, yet they are very different:
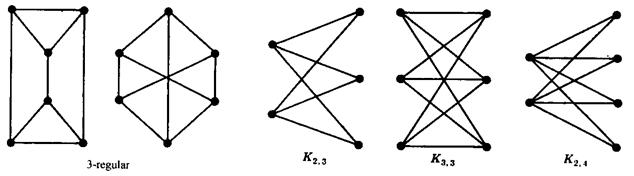 |
| There's a lot of different kinds of graphs out there. If 'friendships' are edges between people (vertices), imagine what the graph of facebook looks like. |
Okay. So, let's pretend we have this structure on the sheep. Then, I pick my first random sheep to test for the illness. That's still a completely random number, so still some work for the computer - but I only have to do it once. After I've picked my first sheep, then if it wasn't sick and I need to keep looking, I pick one of that sheep's neighbors. That's easy for a computer to do - almost no work at all. And I search through the herd in this manner. This process is called a random walk.
So, now you can hear the original question as it was framed on my last Spectral Theory homework: Given a d-regular connected graph G on n vertices (n is the size of the herd - don't be intimidated by letters standing for numbers) and a subset of the graph H with c vertices, what is the probability that a random walk of length k that begins in G\H (you read this notation "G without H" - so starting at one of the vertices of G that isn't in the subgraph H) will stay completely in G\H?
Does the translation make sense? H is the sick sheep - there are c of them in there. What's the probability that if I pick a sheep at random from the healthy ones and then pick k sheep all together by choosing neighbors of the sheep before - what are the chances that I don't wind up with any sick ones in this bunch of sheep I've picked?
Oh, math. It's a funny thing. In Algebraic Topology the other day, we proved a theorem called the Hedgehog Theorem. Maybe I'll take the time to try to explain that in a little while.
No comments:
Post a Comment